Home >>DBMS Tutorial >DBMS Hashing
DBMS Hashing
DBMS Hashing
It can be almost impossible to search all the index values in its level for a huge database structure and then enter the destination data block to retrieve the requested data. Hashing is an efficient technique for estimating the direct location on the disk of a data record without using the index structure.
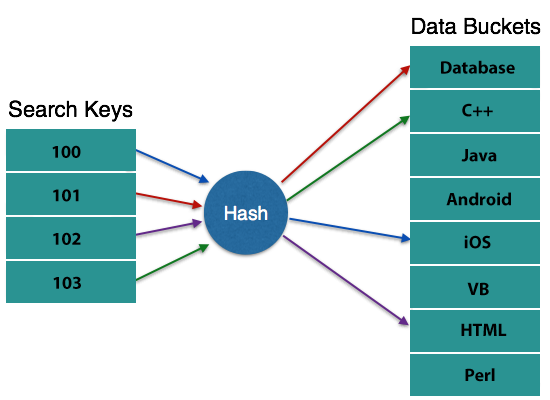
To create the address of a data record, Hashing uses hash functions with search keys as parameters.
Hash Organization
Bucket: In bucket format, a hash file stores data. The bucket is called a storage unit. Usually, a bucket holds one complete disk block, which can hold one or more records in turn.
A hash function, h, is a mapping function that maps the entire set of K key searches to the address where the individual records are placed. This is a function that varies from search keys to bucket addresses.
Static Hashing
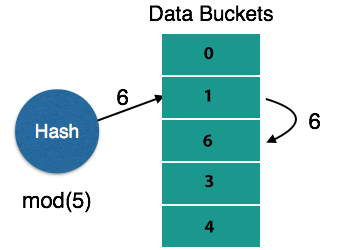
In static hashing, the hash function always computes the same address when a search-key value is given. For instance, if the mod-4 hash function is used, then only 5 values are generated. For that function, the output address must always be the same. At all times , the number of buckets given remains unchanged.
Operation
Address bucket = h(K)
- Insertion-The hash function h determines the bucket address for search key K when a record must be entered using static hash, where the record will be stored.
- Search −The same hash function can be used to retrieve the address of the bucket where the data is stored when a record needs to be retrieved.
- Delete −This is simply a search followed by an operation of deletion.
Bucket Overflow
The bucket-overflow state is known as a collision. For any static hash function, this is a fatal state. In this case , it is possible to use overflow chain.
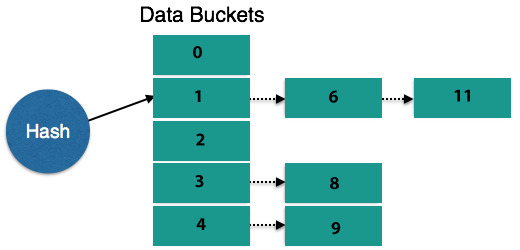
- Overflow Chaining- A new bucket is allocated for the same hash result when buckets are complete and is linked after the previous one. Closed Hashing is called this mechanism.
- Linear Probing- The next free bucket is assigned to it when a hash function generates an address at which data is already stored. Open Hashing is called this mechanism.
Dynamic Hashing
The issue with static hashing is that as the size of the database grows or shrinks, it does not dynamically expand or shrink. Dynamic hashing offers a process through which data buckets are dynamically and on-demand added and removed. Dynamic hashing is referred to as extended hashing as well.
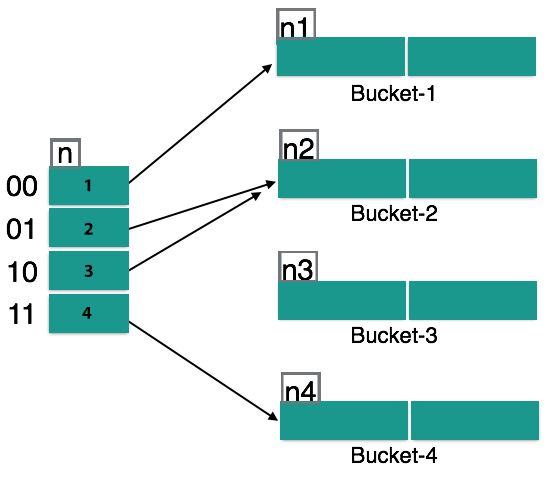
In dynamic hashing, the hash function is created to produce a large number of values and only a few are initially used.
Organization
As a hash index, the prefix of an entire hash value is taken. For computing bucket addresses, only a portion of the hash value is used. To show how many bits are used for computing a hash function, every hash index has a depth value. 2n buckets can be discussed by these bits. If all these bits are consumed, that is, when all the buckets are complete, then the depth value is linearly increased and the buckets are allocated twice.
Operation
- Querying: Look at the hash index's depth value and use those bits to compute the bucket address.
- Update −Execute a query and update the data as above.
- Deletion −Execute a query to locate and delete the desired data.
- Insertion −Compute the address of the bucket
- If the bucket is already full.
- Add more buckets.
- Add additional bits to the hash value.
- Re-compute the hash function.
- If the bucket is already full.
- Else
- Add data to the bucket,
- If all the buckets are full, perform the remedies of static hashing.
When the data is organized in any ordering, hashing is not desirable and the queries require a range of data. Hash works the best when data is discrete and random.
Hashing algorithms are highly complex relative to indexing. Both hash operations are performed on a constant basis.